

Foresight is always better than hindsight and that applies to AI models as well. In the paper “Diffusion Language Models Know the Answer Before Decoding”, the authors Shiwei Liu et al. introduce the results of their research: Diffusion Language Models (DLMs) often already know the correct answer long before they finish decoding. Based on this insight, they propose Prophet, a decoding strategy that allows models to “go all in” as soon as they are sufficiently confident.
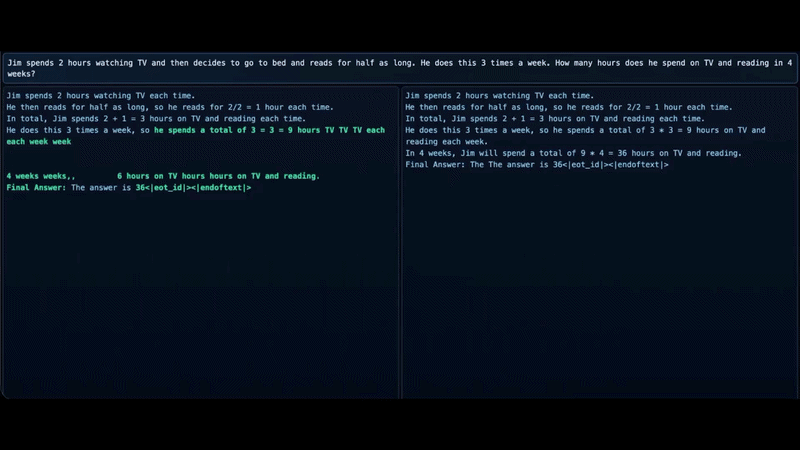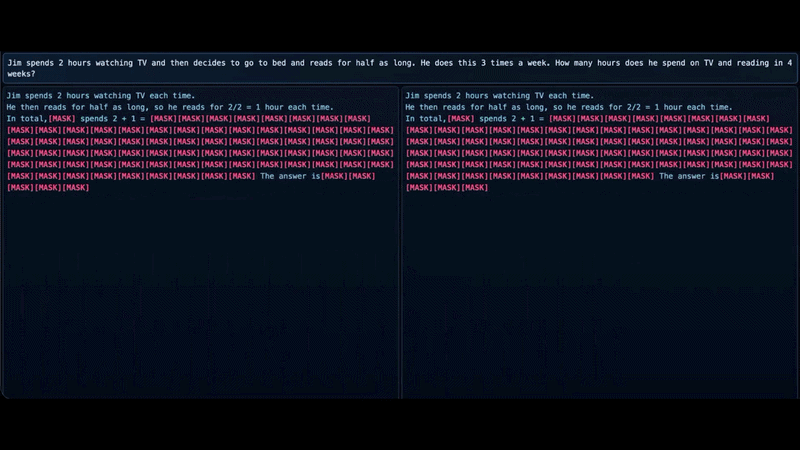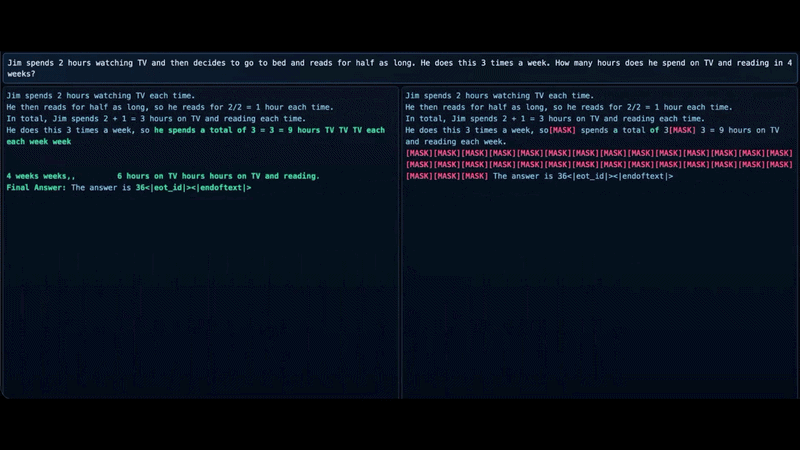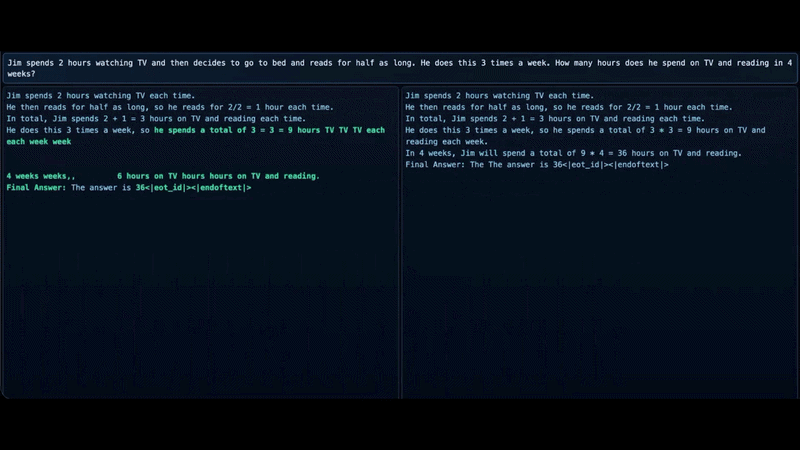
Left: Prophet; Right: LLaDa
Diffusion Language Models have recently emerged as a promising alternative to traditional autoregressive (AR) language models such as ChatGPT. While AR models generate text one token at a time, DLMs generate all tokens in parallel and iteratively refine them by backtracking.
This parallel generation paradigm offers theoretical advantages in flexibility and decoding efficiency. However, in practice, DLMs remain slower than autoregressive models. The main reasons are the computational cost of processing context in both directions and the large number of refinement steps required to reach high-quality outputs.
The central contribution of the paper is a phenomenon the authors call early answer convergence. They show that in most cases, DLMs internally converge to the correct answer well before the final decoding step.
On benchmarks such as Grade School Math and logic based Massive Multitask Language Understanding, up to 97–99% of samples can be decoded correctly using only half of the refinement steps. In other words, the model often reaches the correct solution early but continues refining unnecessarily anyways.
This observation reframes DLM inference as a different kind of problem. It’s not just about how to generate better outputs, but when to stop refining.
To leverage early answer convergence, the authors introduce Prophet, a training-free decoding strategy that dynamically determines whether refinement should continue or whether the model should commit and “go all in” immediately.
At each refinement step, Prophet measures the confidence gap between the top two prediction candidates. If the model is confident enough, Prophet “goes all in” and decodes all remaining tokens in a single step. This approach is referred to as Early Commit Decoding.

The significance of this work lies not in a new model architecture, but in questioning an implicit assumption: that all refinement steps are necessary. By recognizing that diffusion models often converge early, the authors transform decoding from a fixed-length generation process into a dynamic stopping problem.
With Prophet, the decoding steps can be decreased by up to 3.4×, while preserving high generation quality. In doing so, the work on Prophet presents a practical and elegant path toward faster diffusion-based language modeling, proving that sometimes, the model already knows the answer long before it tells us.
Shiwei Liu et al. will be presenting their work during ICLR 2026 in April, the Fourteenth International Conference on Learning Representations. This work has received acknowledgement as an Oral Contribution. If you’ll be there, drop by the talk on Saturday, April 25th, 10:30 am local time at Oral Session 5A.